Introduction
This article assumes that the user is aware of the process by which a webpage renders on a browser, how the resources are fetched, etc. The document also assumes that the user have basic understanding of browser caches and cache headers. This article provides the basic information on using appcache and a demo page to explain its benefits.
AppCache vs Browser Cache
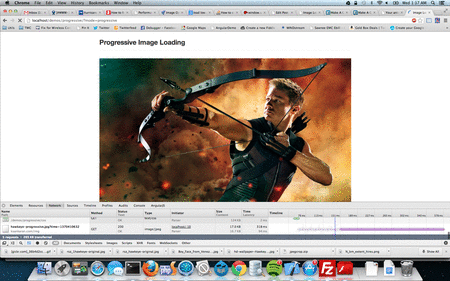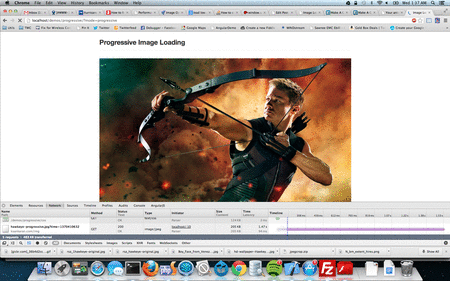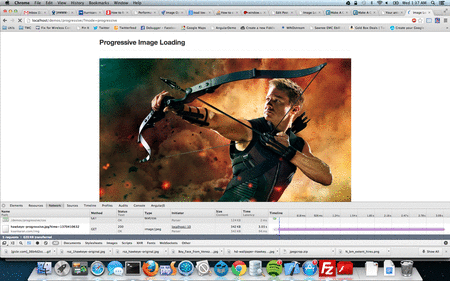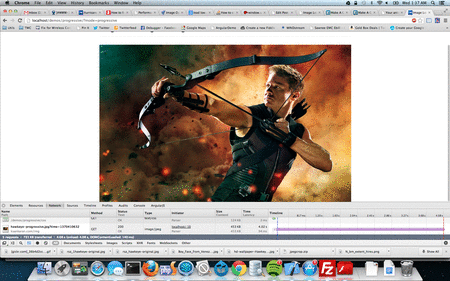
When a page is requested on the browser without appcache, there will be a sequence of network requests sent from the browser to the server. The first request is the actual page (raw html) you wanted to load. Then browser reads the html and process them line by line. Every script tag, css link tag or any other resources on the page are requested sequentially. Each of this requests may be cached in the browser and this forms the browser cache. I said “may be” because the rule for a resource getting cached is: resource headers sent from your server. See example below:
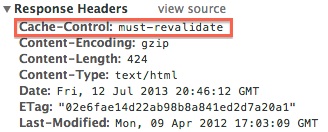
So, it is evident that a browser cannot cache these items unless and otherwise, we visit the page and also depends on headers received for individual resources. But, what if you want to cache the extra few items that needed to display next page? What if, your website need to work offline and sync only when needed or when the user gets online? What if, you have a website which have separate layer for presentation/logic and separate layer for data and like to store all the presentation/logic offline? The answer is simple and straightforward: AppCache.
Now, let’s not get excited and convert all our websites to webapp. HTML5 AppCache is designed for offline webapps – make no mistake. A simple error such as app-caching a dynamic data would result in rendering outdated website. So, it takes time to understand AppCache and make sure you appcache the right set of resources.
How to do it?
Well, its pretty simple. Write a manifest file describing the items to be cached, network behavior, fallback, etc and mention the manifest in the HTML. That’s it.
A sample would be below:
CACHE MANIFEST # ====================================== # AppCache Manifest - version 0.1 # ====================================== CACHE: #JS files #CSS files #Images NETWORK: # Resources that require the user to be online. FALLBACK: # static.html will be served if main.py is inaccessible /main.py /static.html # offline.jpg will be served in place of all images in images/large/ images/large/ images/offline.jpg # offline.html will be served in place of all other .html files *.html /offline.html |
NOTE: The CACHE MANIFEST string should be the first line and is required.
CACHE:
This is the default section for entries. Files listed under this header (or immediately after the CACHE MANIFEST) will be explicitly cached after they’re downloaded for the first time.
NETWORK:
Files listed under this section are white-listed resources that require a connection to the server. All requests to these resources bypass the cache, even if the user is offline. Wildcards may be used.
FALLBACK:
An optional section specifying fallback pages if a resource is inaccessible. The first URI is the resource, the second is the fallback. Both URIs must be relative and from the same origin as the manifest file. Wildcards may be used.
Now add the manifest to the html file.
<html manifest="example.appcache"> ... </html> |
Cache Update
The tricky part is updating the cache items. When the content on the server is changed, the browser will not know the change and will continue to use the outdated data on the webpage. The appcache manifest should be fetched everytime by the browser to determine the items that has to be refreshed. Hence, it is VERY IMPORTANT to make sure appcache manifest is never cached by the browser or at least not for a long time. For that, it is important that the headers sent by the webserver for the manifest also includes the expiry time. It is also possible to update the appcache via the javascript like
var appCache = window.applicationCache; appCache.update(); // Attempt to update the user's cache. ... if (appCache.status == window.applicationCache.UPDATEREADY) { appCache.swapCache(); // The fetch was successful, swap in the new cache. } |
It is also possible to clear the cache when the user clears the same in his/her browser. However, that is not a valid workflow for updating the cache.
The Gotchas
The appcache also caches the base page. This means, if you later change the base page to include an additional library or UI, it will not be fetched from server unless there is a manifest file update. In order to bypass this functionality, it is ok to include the appcache in a temporary html and include the temp html as an iframe in the base page (See demo link below). By this way, you still cache the manifest items but the base page will not be cached by the appcache unless specified in the manifest.
Demo link
Conclusion
We saw the basic differences between appcache and browser cache with a basic example to include app caches. The example link also shows how to include the appcache by not affecting the cache of the base page by providing manifest in a temp html and loading the same in a iframe.